

Чтобы даже тот, кто регулярно прогуливает вебинары Бластим, не остался без знаний, мы периодически делимся конспектами прошлых лекций наших крутых ученых. Сегодня, перед стартом курса по ML, мы отрываем от сердца и расшариваем ценный материал с июньской встречи «Как не решить вашу таску с помощью машинного обучения?» от легендарного Владимира Шитова.
Здесь — доступным и понятным языком о том, как работает ML и что может пойти не так при применении этого fancy метода.
Здесь — доступным и понятным языком о том, как работает ML и что может пойти не так при применении этого fancy метода.
Машинное обучение VS Статистика
При очень грубом упрощении в рутинной статистике ученые проверяют гипотезы и маниакально зациклены на p-value (мы уже писали про пихакинг). Например, в одной статье с помощью статметодов удалось показать, что ЦЕЛЫХ 4% вариабельности интеллекта объясняется генами. Открытие? Открытие! Можно публиковаться, и неважно, что прикладной значимости тут не проглядывается.
В машинном обучении всё иначе: мы берем буквально ту же самую выборку из статистики, делим ее на две части. И теперь на одной части — мы учимся (train), а на другой — пытаемся предсказывать (test). Модель хороша, только если она показывает себя провидцем. Другими словами, вместо статистической значимости в машинном обучении — египетская предсказательная сила.
В машинном обучении всё иначе: мы берем буквально ту же самую выборку из статистики, делим ее на две части. И теперь на одной части — мы учимся (train), а на другой — пытаемся предсказывать (test). Модель хороша, только если она показывает себя провидцем. Другими словами, вместо статистической значимости в машинном обучении — египетская предсказательная сила.
Как вообще устроен пайплайн?
Давайте перечислим ключевые этапы в машинном обучении:
- Поставить задачу: распознавать котиков на фото.
- Задать метрику — числовой критерий степени решения задачи: процент правильно распознанных фото с котиками.
- Собрать данные: фото с котиками и другими объектами.
- Натренировать модель: сейчас моделей воз и маленькая тележка. К примеру, для изображений подходит сверточная нейросеть. И, кстати, можно вообще ничего не понимать, что внутри этой модели — это концепция black box. Но мы порой жертвуем интерпретируемостью ради решения задачи.
- Оценить метрики: если модель хорошая, то можно писать статью или открывать стартап, если не работает — пытаться улучшить.

Где машинное обучение уже SOTA?
Можно признать ряд state-of-the-art результатов:
- Изображения: AlexNet (2012 г.) — это переломная точка для нейросетей, когда они доказали свою силу и из теоретических выкладок превратились в практические инструменты. Мы писали об этой истории тут. Проблема с картинками благодаря ИИ на сегодня во многом решена.
- Тексты: ChatGPT (2022 г.) — в пояснении не нуждается.
- Белки: AlphaFold (2018 г.) и особенно AlphaFold2 (2020 г.) — справился с полувековой задачей предсказания структуры белка по последовательности.
Машинное обучение VS Алгоритмы
Помимо статистики, машинное обучение часто сравнивают с алгоритмами.
Классические алгоритмы: вы пишете алгоритм — последовательность действий, он решает задачу. Пришла новая задача — начинай сначала.
Машинное обучение работает не так. Вы натренировали модель на одну задачу, но на этом дело не заканчивается. Наоборот, проявляются те самые преимущества ML:
Классические алгоритмы: вы пишете алгоритм — последовательность действий, он решает задачу. Пришла новая задача — начинай сначала.
Машинное обучение работает не так. Вы натренировали модель на одну задачу, но на этом дело не заканчивается. Наоборот, проявляются те самые преимущества ML:
- Модель можно переносить на другие задачи. Скажем, вы изобретаете алгоритм для распознавания котиков, а его тут же перенимают другие люди, работающие с песиками.
- Если модель не очень справляется, то можно не ломать голову над улучшением алгоритма, а просто подкинуть больше обучающих данных. Чаще всего это сразу значительно улучшает качество.
Конечно, подход «тупо больше данных» не всегда канает. Так, при переходе от AlphaFold к AlphaFold2 инженеры DeepMind именно докручивали алгоритм, а данные для обучения остались примерно теми же. Усилия были вознаграждены Нобелевкой 2024 года.
Дольче вита? На самом деле нет:(
Что может пойти не так?
Когда вы тренируете модель, у вас есть какое-то ограниченное количество доступных данных (например, ваши личные фото котиков). Вы режете эти данные на тренировочную и тестовую выборку. При этом вы надеетесь, что доступные вам данные похожи на те, что встретятся модели в реальных приложениях (например, модель будет распознавать котиков в соцсетях).
Если ваша модель хорошо себя покажет на тестовой выборке, то, вероятно, она хорошо будет работать в жизни. Но тут нас поджидают подводные камни.
Если ваша модель хорошо себя покажет на тестовой выборке, то, вероятно, она хорошо будет работать в жизни. Но тут нас поджидают подводные камни.
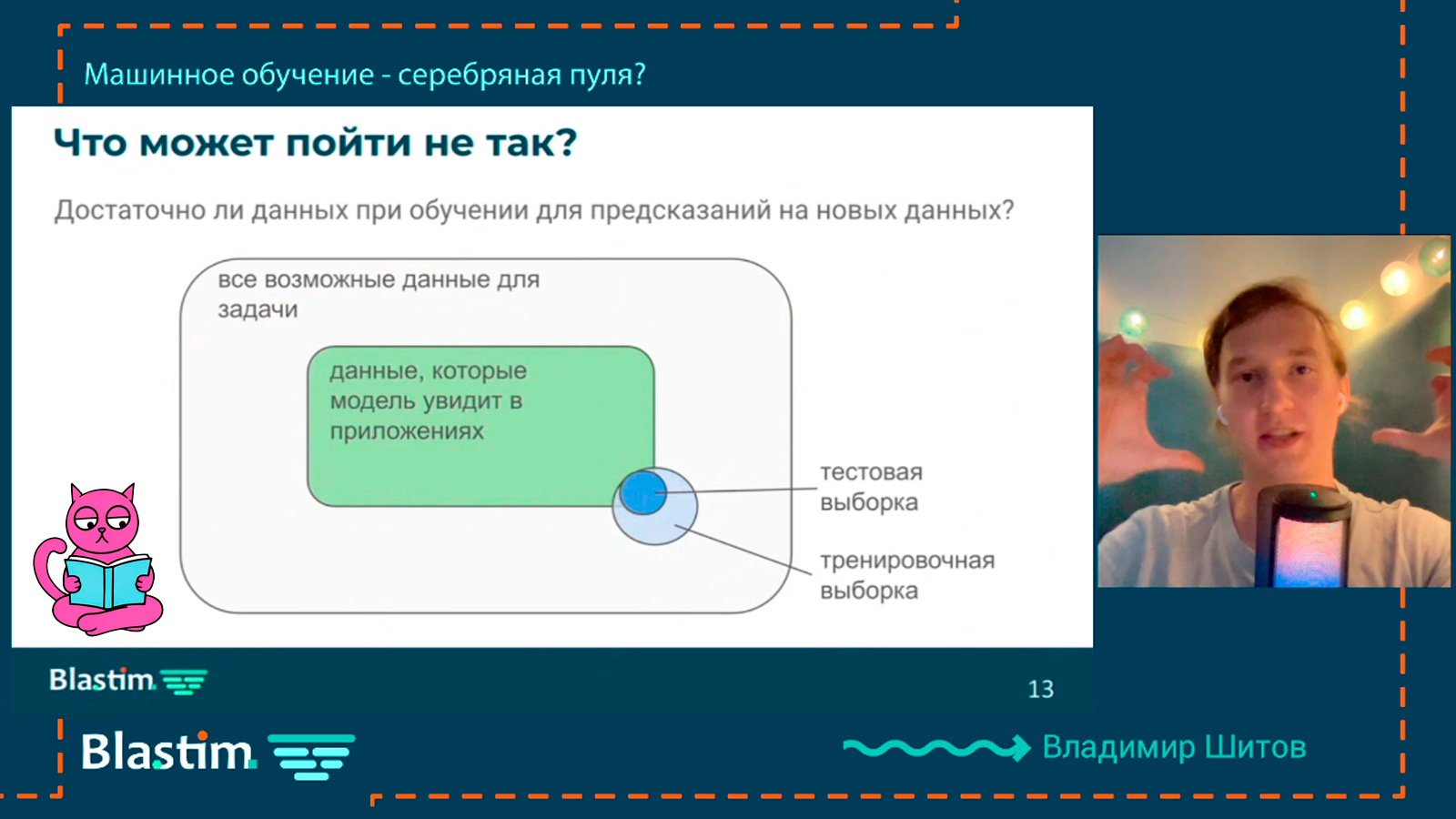
💩 Смещенная выборка
Если ваша тренировочная выборка не похожа в принципе на реальные данные, которые увидит модель в приложениях, то это называется смещенная выборка или выборка с bias. Как бы вы ни соорудили в этом случае тестовую выборку, ваша модель не сможет хорошо предсказывать на неизвестных данных. Пример: вы учите нейросеть на фото с котиками, которые сделаны в фотостудии, а распознавать придется в суровой дикой природе.
С данными может быть еще много проблем. Как бы вы ни умели великолепно моделировать, железно работает принцип GIGO:
С данными может быть еще много проблем. Как бы вы ни умели великолепно моделировать, железно работает принцип GIGO:
Плохие данные на входе 💩 — Плохая модель на выходе 💩
Обратимся к single cell и посмотрим примеры из статьи Владимира «Biases in machine-learning models of human single-cell data»
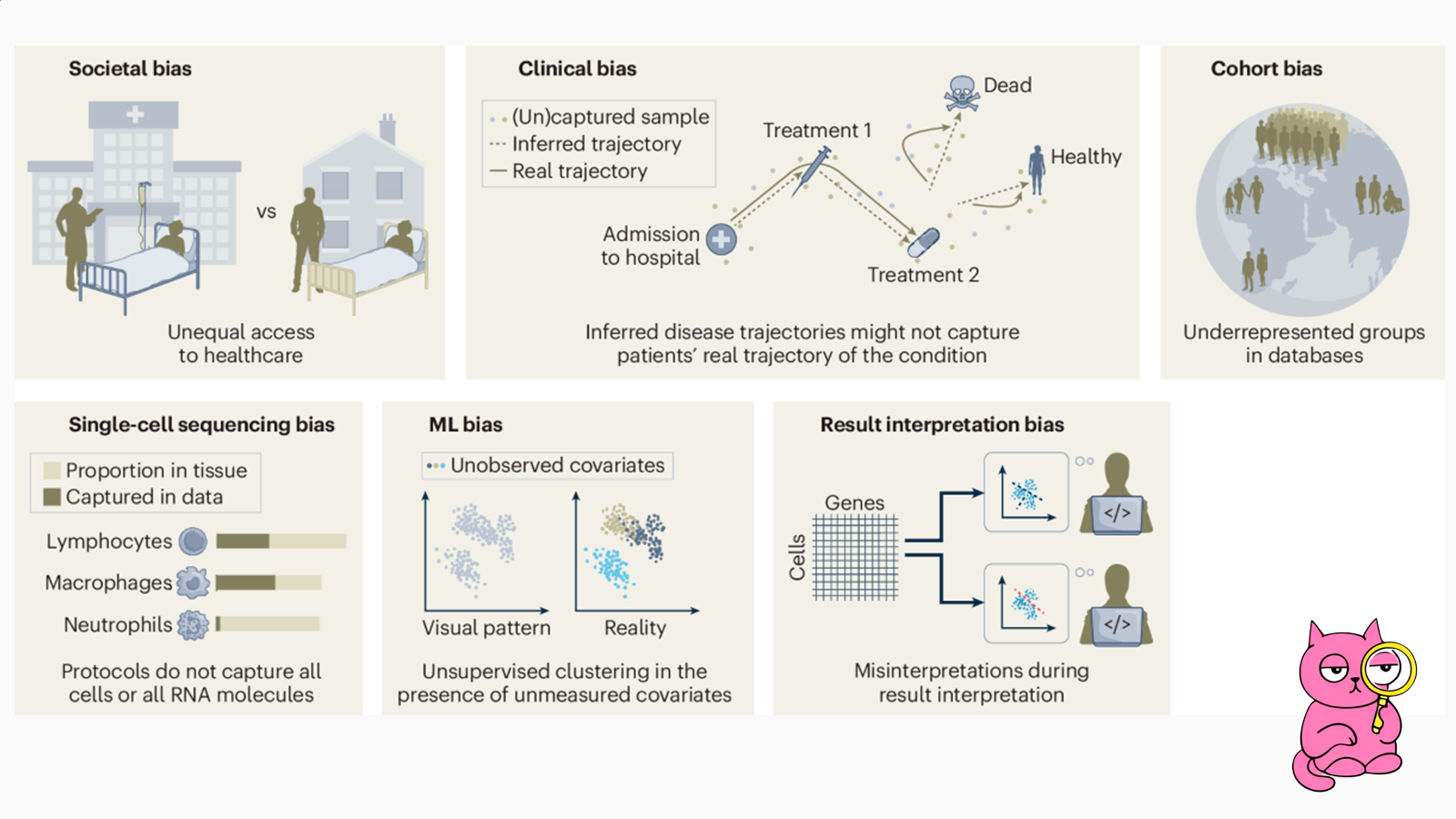
Примеры bias из статьи:
- Общественный. Данные секвенирования обычно приходят из приличных клиник, куда поступили вполне приличные люди, живущие в крупных городах... а не жители далекой индийской деревни.
- Клинический. Например, в исследованиях заболевания легких с помощью single cell секвенируют кусочки легких больных и здоровых контролей. Но «здоровые» пациенты отнюдь не 20-летние атлеты, а жертвы автокатастроф или умершие от передоза наркотиков.
- Когортный. В базе данных CellxGene большая часть данных получена от людей европейской популяции. Южной Америки, Африки или Индии гораздо меньше.
- Приборный. В области транскриптомики мы часто теряем из виду суперредкие популяции клеток из-за самой особенности методологии. А эти цитотипы могут быть важными. См. ионоциты.
- Bias применения ML-методов.
- Bias интерпретации результатов экспертами.
🧠 Утечка мозгов test в train

Еще одна проблема — утекание (data leakage) тестовых данных в тренировочную выборку. Пример: проводилось соревнование по сегментации гистологических изображений. Была тренировочная выборка, на которой участники учили модель, и тестовая, на которой получали оценку. Однако данные были подготовлены халтурно: большие картинки с микроскопа нарезали на куски случайным образом, так что части снимков оказывались и в одной выборке, и в другой. Модель при тренировке видела куски из test и предсказывала их лучше, чем случайные фрагменты. Она их тупо запомнила!
Если вы собираетесь обучать свою модель, критически важно подумать, как вы будете создавать train и test. Некорректное формирование выборок — частый огрех в статьях. Мы на курсе отводим отдельную пару под тему «валидация».
Если вы собираетесь обучать свою модель, критически важно подумать, как вы будете создавать train и test. Некорректное формирование выборок — частый огрех в статьях. Мы на курсе отводим отдельную пару под тему «валидация».
🤖 Выдать базу: плохие бейзлайны
В 2023 году ChatGPT вселил во всех уверенность, что огромные перепараметризованные модели творят чудеса. Уже на следующий год ученые из области single cell под руководством Bo Wang сделали foundation модель с говорящим названием scGPT. По аналогии с естественным языком клетки рассматривались как предложения, а гены — как слова. Сработало? С наукометрической точки зрения, однозначно.
Статья стала блокбастером, привлекла максимум внимания. Но результаты LLM оказались скромными. Например, на очень актуальной задаче предсказания изменения активности генов в ответ на воздействие лекарств или отключение части генов (это еще называется пертурбациями), нейросеть показала себя хуже очень простых моделей.
Несмотря на фейл, статья про scGPT до сих пор бурно цитируется и породила нейросетевую подобласть, где авторы учат похожие трансформеры и соревнуются друг с другом. Но они совершенно забыли про бейзлайн-модели, которые справляются лучше навороченных LLMок.
Статья стала блокбастером, привлекла максимум внимания. Но результаты LLM оказались скромными. Например, на очень актуальной задаче предсказания изменения активности генов в ответ на воздействие лекарств или отключение части генов (это еще называется пертурбациями), нейросеть показала себя хуже очень простых моделей.
Несмотря на фейл, статья про scGPT до сих пор бурно цитируется и породила нейросетевую подобласть, где авторы учат похожие трансформеры и соревнуются друг с другом. Но они совершенно забыли про бейзлайн-модели, которые справляются лучше навороченных LLMок.
🔬 Забивать гвозди микроскопом: применение методов не по назначению
В заключение пару слов про совсем нелепое: применение полезных методов не по назначению. Пример: использование координат UMAP для чего-то, кроме рисования красивых графиков. UMAP — нелинейный метод снижения размерности, который годится лишь для отображения многомерных данных в 2D. Он сохраняет локальную структуру данных, но искажает глобальные расстояния.
Однако это не помешало в 2024 году одним авторам исследовать эволюцию пения котиков птиц с его помощью. Ученые взяли UMAP-координаты и использовали их для дальнейшего анализа. Получился полный абсурд, поднялся шум в соцсетях, но статья до сих пор не отозвана.
Однако это не помешало в 2024 году одним авторам исследовать эволюцию пения котиков птиц с его помощью. Ученые взяли UMAP-координаты и использовали их для дальнейшего анализа. Получился полный абсурд, поднялся шум в соцсетях, но статья до сих пор не отозвана.
Теперь вы знаете, как работает машинное обучение на пальцах и что нельзя слепо верить красивым значениям метрик в публикациях — они могут быть получены на искаженных тренировочных выборках и совершенно не гарантировать релевантность модели в реальном мире.
Как же избежать провалов и делать по-настоящему полезные модели? Как вы уже догадались, ответ прост: учиться, учиться и еще раз учиться. Как самому, так и вашим моделям. Отличный вариант — у нас на курсе с Вовой Шитовым, уже с 17 февраля
Пишите Варваре Бластим свои вопросы про курс, а также чтобы забрать конспекты других вебинаров с Вовой Шитовым: https://t.me/varvara_blastim

